
Failed requests are a fact of life, network weirdness and machine failures are inevitable. It can be tempting to simply retry the request when this happens, but this may cause more harm than good.
If you sent a message to a company and got no response after a while, you'd probably send another. This is more likely to get your a response, compared to waiting it out. If everyone does that though, the company could be so swamped by messages that it'll take even longer for all the customers to get their answer.
While this could be taken as a tale on how it's important to have responsive customer support that provides answers the first time around, in reality a small fraction of messages are always going to be lost and how clients deal with that can causes problems in and of itself.
The same applies to web services. Everything from small blips to multi-minute outages are a fact of life, and how your clients deal with a failure can make the difference between a minor annoyance and a prolonged outage.
No raindrop thinks it caused the flood
As discussed in a previously, due to queuing theory a small increase in traffic can cause a much larger increase in latency. A naive retry policy can lead to spike of beyond what you can handle. Let's say your clients retried after 10 seconds, and you had a brief network blip. What couldd happen?
Well 10 seconds later, you'd get your normal level of traffic plus all the retries - that's double your usual traffic! If you're lucky most of them will succeed, and 10 seconds after that you'll have a smaller spike and so on until traffic is back to normal.
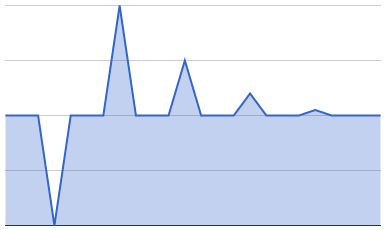
Good outcome: Retry spikes reduce over time
If you're not so lucky, less than half of the queries will succeed. 10 seconds later you'll have even more traffic, and even more 10 seconds after that. This will quickly cascade into a full-blown outage, with retries and backlogged queries clogging up your whole system. This is hard to recover form, and typically involves simultaneously restarting all your servers.
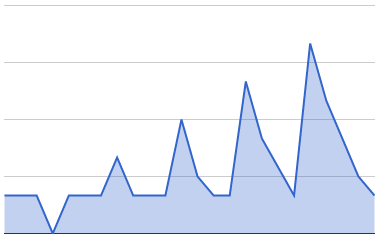
Bad Outcome: Retry spikes increase over time
Prevention is better than cure
That's a nasty failure mode, so how do you prevent this without disabling retries? There's three things that can help.
The first is exponential backoff. If your first retry is after 10s, wait 20s before attempting another retry and for the one after that wait 40s. This means that as your requests fail, you reduce your request rate and thus it's more likely that the overloaded server will recover, particularly after prolonged outages. It's advised to put an upper bound on the backoff so you don't end up waiting for days.
The second is randomness. If your exponential backoff says to wait 20s, multiply that by a random number between say 0.5 and 1.5. This spread the load around, rather than having all the retries hitting the servers at exactly the same time.
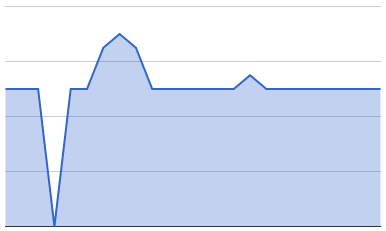
Best outcome: Retries spread over time with backoff
The final thing that can help is to rate-limit your retires. If a server fails 1% of requests under normal circumstances, then if you're doing more than 10% retries then the chances are the server is overloaded and sending retries isn't helping. Failing fast is a better option in those circumstances, and libraries such as Netflix's Hyxtrix can help with this.



No comments.