
There's more to selecting a piece of software than headline numbers.
At PromCon there was a talk in which the speaker had found that VictoriaMetrics had compression far beyond what other solutions like Thanos have, as in 3-4x. During the social event there were questions from some attendees as to whether there are optimisations that could be adopted by Prometheus or if this might be too good to be true, and what about other factors such as correctness and performance in reading the data back out.
Based on this I did some quick ad-hoc testing on the Friday of PromCom and gave a lightning talk on it, the results of which were that the Prometheus server's compression (which both Cortex and Thanos use) is slightly better by about 10% than VictoriaMetrics and that in addition VictoriaMetrics was not storing all the information that Prometheus does.
There's only so much testing you can do with 15 minutes setup time and lightning talks are only 5 minutes, so I wanted to take a deeper look into everything. The main developer of VictoriaMetrics also corresponded with me asking for more details (the videos aren't up yet at time of writing) plus a fuller write up, and suggested some adjustments to my test setup to make it a bit more realistic and I was also able to point him to the PromQL unittests so he could verify the correctness of their 3rd party PromQL implementation rather than waiting on bug reports to come in.
This post will also give you an idea of the sort of things to look out for when evaluating any piece of software.
So on to the testing. It's important that testing is as apples to apples as is possible. The test is primarily about compression, so I'll setup a Prometheus that's forwarding everything to VictoriaMetrics via remote write, all with default settings. I'm not going to look at RAM or CPU usage, as it's not a fair comparison. Cortex, Thanos's receiver, or M3DB would be what to compare against as they also hook in to remote write and there's others better placed to do such testing and compare things like replication, auto-rebalancing, tolerance to machine failure etc. across the systems.
I also believe in providing enough detail about the setup to allow someone else to reproduce it themselves to verify. In this case I'll once again use the latest stable versions of each, which is now Prometheus 2.14.0 and VictoriaMetrics 1.29.3. It looks like VictoriaMetrics tunes itself based on RAM in the machine, so I'll mention that I've 32GB. Beyond that it's ZFS-on-Linux mirroring over two SSDs in the unlikely event that matters. I'm using my usual expose_many_metrics script scraped once a second, tweaked to have 9 digits after the decimal point on observe to simulate latency metrics more closely (as suggested, my previous test used a completely random float). Note that this setup has no churn. Prometheus is also scraping itself.
Both systems have a snapshot feature, so that seems the fairest way to compare disk usage as fixed overhead like Prometheus's WAL should not be taken into account. We can take snapshots at the same time with:
curl -XPOST :9090/api/v1/admin/tsdb/snapshot & curl :8428/snapshot/create wait
Due to the ways both systems do snapshots, a few uncommon options are needed to get du to do the right thing here:
$ du -hlLs prometheus-2.14.0.linux-amd64/data/snapshots/* victoria-metrics-data/snapshots/* 90M prometheus-2.14.0.linux-amd64/data/snapshots/20191115T130459Z-78629a0f5f3f164f 78M victoria-metrics-data/snapshots/20191115130459-15D7566ABFAD1118
That's after half an hour, so let's look at some other things I noticed in passing while we're waiting for that to build up into a more realistic amount of data where processes like compaction have had a chance to kick in.
So let's try some queries to see if the data is the same in both systems, which we'd expect to be identical bar whatever tiny delay should be involved in ingesting data into VictoriaMetrics via remote write. Both systems support the query API, so we can do:
$ for i in 9090 8428; do curl -g ":$i/api/v1/query?query=prometheus_tsdb_blocks_loaded"; echo; done
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"__name__":"prometheus_tsdb_blocks_loaded","instance":"localhost:9090","job":"prometheus"},
"value":[1573818712.325,"0"]}]}}
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"__name__":"prometheus_tsdb_blocks_loaded","instance":"localhost:9090","job":"prometheus"},
"value":[1573818652,"0"]}]}}
The value is 0 in both cases, as you'd expect. The timestamps are a different though, beyond what could be explained by ingestion delay. The first thing to note is that Prometheus has a fractional part to the timestamp whereas VictoriaMetrics does not. This looks to be as there's no explicit time passed so the current time should be used, and Prometheus is using a millisecond resolution time whereas VictoriaMetrics is using seconds. If an explicit timestamp is sent it's fine, though the rounding is different if there's more precision than that. These are both small things, you couldn't tell the difference in Grafana as it'll send in integers for time.
There's a bigger issue here though - the timestamps are different by a minute! Let's try with an explicit date and trimming down the output for sanity:
d=$(date +%s); echo $d; for i in 9090 8428; do curl -g ":$i/api/v1/query?query=prometheus_tsdb_blocks_loaded&time=$d"; echo; done 1573819392 "value":[1573819392,"0"] "value":[1573819332,"0"]
This isn't any better, VictoriaMetrics is altering the query we're sending in. Let's try with time() so we're not depending on the database:
d=$(date +%s); echo $d; for i in 9090 8428; do curl -g ":$i/api/v1/query?query=time()&time=$d"; echo; done
1573819467
{"resultType":"scalar","result":[1573819467,"1573819467"]}
{"resultType":"vector","result":[{"metric":{},"value":[1573819407,"1573819407"]}]}
So the value has the wrong type for VictoriaMetrics (scalar vs instant vector), and is still off by a minute. This is not a correct output. Weirdly if I use an earlier time like 100 the correct value is returned. It looks like the discontinuity is for time values in the last minute, so queries for the last minute of data will return incorrect misleading results.
Let's look more at the type mismatch:
$ for i in 9090 8428; do curl -g ":$i/api/v1/query?query=sum(time())"; echo; done
{"status":"error","errorType":"bad_data","error":"invalid parameter 'query': parse error at char 12: expected type instant vector in aggregation expression, got scalar"}
{"status":"success","data":{"resultType":"vector","result":[{"metric":{},"value":[1573819787,"1573819787"]}]}}
So VictoriaMetrics is returning a result where it should be producing a type error, as you can't aggregate a scalar. What does this mean for the usual time() - timestamp pattern used for alerting?
$ for i in 9090 8428; do curl -g ":$i/api/v1/query?query=time()-prometheus_tsdb_blocks_loaded"; echo; done
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"instance":"localhost:9090","job":"prometheus"},"value":[1573819930.391,"1573819930.391"]}]}}
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"instance":"localhost:9090","job":"prometheus"},"value":[1573819870,"1573819870"]}]}}
That's not right. A series with no labels should not match a series with labels, this is an explicit design decision in PromQL to keep the language consistent and predictable. More explicitly:
$ for i in 9090 8428; do curl -g ":$i/api/v1/query?query=vector(0)-prometheus_tsdb_blocks_loaded"; echo; done
{"status":"success","data":{"resultType":"vector","result":[]}}
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"instance":"localhost:9090","job":"prometheus"},"value":[1573819980,"0"]}]}}
So vector matching is broken in VictoriaMetrics when one side has an instant vector with one sample with no labels. Even the scalar() function doesn't return a scalar:
$ for i in 9090 8428; do curl -g ":$i/api/v1/query?query=scalar(vector(1))"; echo; done
{"status":"success","data":{"resultType":"scalar","result":[1573820388.447,"1"]}}
{"status":"success","data":{"resultType":"vector","result":[{"metric":{},"value":[1573820328,"1"]}]}}
So there's a few issues with the PromQL implementation of VictoriaMetrics, which our unittests will hopefully help them find and fix.
Let's look at data storage, as for a apples to apples comparison we want to know that both databases contain the same data. Given that we know that VictoriaMetrics doesn't return correct data for the last minute via the query API, let's look a little further back:
$ d=$(date +%s -d'61 seconds ago'); for i in 9090 8428; do curl -g ":$i/api/v1/query?query=go_memstats_gc_cpu_fraction&time=$d"; echo; done "value":[1573821987,"0.0008032872187757047"]}, "value":[1573821987,"0.0003083021835007435"]}]}} "value":[1573821987,"0.0008032872187757"]}, "value":[1573821987,"0.0003083021835007"]}]}
So for both of these time series we see that VictoriaMetrics is lossy. To be certain I have verified that this isn't just a floating point rendering issue, these are different numbers with different bit representations.
Let's see about staleness handling. I briefly stopped the exposer:
$ d=1573822392; for i in 9090 8428; do curl -g ":$i/api/v1/query?query=up{job=\"expose\"}[5s]&time=$d"; echo; done
"values":[[1573822387.664,"1"],[1573822388.664,"0"],[1573822389.664,"0"],[1573822390.664,"0"],[1573822391.664,"1"]]}]}}
"values":[[1573822387.664,"1"],[1573822388.664,"0"],[1573822389.664,"0"],[1573822390.664,"0"],[1573822391.664,"1"]]}]}}
And both have the data expected when queried for a range vector:
$ d=1573822392; for i in 9090 8428; do curl -g ":$i/api/v1/query?query=go_goroutines{job=\"expose\"}[5s]&time=$d"; echo; done
"values":[[1573822387.664,"6"],[1573822391.664,"6"]]}]}}
"values":[[1573822387.664,"6"],[1573822391.664,"6"]]}]}}
So let's check this with a range query to see where the series disappears and reappears:
$ for i in 9090 8428; do curl -g ":$i/api/v1/query_range?query=go_goroutines{job=\"expose\"}&start=1573822388&end=1573822392&step=1"; echo; done
"values":[[1573822388,"6"],[1573822392,"6"]]}]}}
"values":[[1573822388,"6"],[1573822389,"6"],[1573822390,"6"],[1573822391,"6"],[1573822392,"6"]]}]}}
VictoriaMetrics is incorrectly returning time series that are stale. Let's check for NaNs more generally:
$ d=$(date +%s -d'61 seconds ago'); for i in 9090 8428; do curl -g ":$i/api/v1/query?query=prometheus_rule_evaluation_duration_seconds{quantile=\"0.5\"}&time=$d"; echo; done
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"__name__":"prometheus_rule_evaluation_duration_seconds","instance":"localhost:9090","job":"prometheus","quantile":"0.5"},"value":[1573822973,"NaN"]}]}}
{"status":"success","data":{"resultType":"vector","result":[]}
So when comparing how good the compression is we need to keep in mind that VictoriaMetrics is both lossy, and dropping NaNs (and possibly other non-real values) whereas Prometheus is lossless and handling the non-real values including stale markers correctly.
While waiting on the data for compression to build up, one thing I noticed was that there was a big difference in the index sizes of the snapshots. Prometheus has 8.8MB while VictoriaMetrics has 427KB. Both seem to be using inverted indexes, and I know the Prometheus implementation is pretty well optimised so this makes me wonder what the tradeoff is as merely clever memory tricks shouldn't produce a 20x difference. Does it generate index at startup or on the fly, rather than Prometheus's approach of mmaping the posting lists? Might it use compression over the whole index so it's smaller, but slower? I haven't gotten my head around all the code yet, even with some pointers from the author.
So let's get some indicative numbers. Prometheus has a good set of micro-benchmarks for index lookups so I inserted the same data into both Prometheus and VictoriaMetrics and ran the same queries via the HTTP API. For example:
$ for i in {0..5}; do time curl -g ':9000/api/v1/query?query=sum({n="1"})&time=1573829440'; done 2>&1 > /dev/null | fgrep real | cut -d 'm' -f 2 | sort -g | head -1
1.933s
Running them all and comparing, I get:
Prom VM Ratio n="1" 0.560 1.933 3.45 n="1",j="foo" 0.265 1.167 4.40 j="foo",n="1" 0.270 1.156 4.28 n="1",j!="foo" 0.275 1.174 4.27 i=~".*" Rejected Timeout n/a i=~".+" 25.617 Timeout n/a i=~"" Rejected 0.014 n/a i!="" 24.202 Timeout n/a n="1",i=~".*",j="foo" 0.332 1.149 3.46 n="1",i=~".*",i!="2",j="foo" 0.379 1.188 3.13 n="1",i!="" 0.845 1.939 2.29 n="1",i!="",j="foo" 0.476 1.188 2.50 n="1",i=~".+",j="foo" 0.492 1.164 2.37 n="1",i=~"1.+",j="foo" 0.103 0.391 3.80 n="1",i=~".+",i!="2",j="foo" 0.497 1.155 2.32 n="1",i=~".+",i!~"2.*",j="foo" 0.528 1.078 2.04
This shows that Prometheus is faster in all cases, by ~2.0-4.4x. While I personally believe in throughput over latency in cases like this, for completeness I did a run with GOMAXPROCS set to default on my 4 core desktop (which is also doing desktopy things) then VictoriaMetrics is ~1.6-2x lower latency compared to single core. However even granting that indulgence Prometheus's TSDB remains ~1.3-3.3x lower latency, even given VictoriaMetrics is using more cores.
So it would appear at what is a moderate index size of 5M time series with no ingestion or other activity ongoing, a standalone Prometheus server is faster at index lookups than VictoriaMetrics at the cost of what is in the grand scheme of things a small bit more disk space for the index.
Now that's it's been a while, let's see how the disk usage is doing:
13016742 prometheus-2.14.0.linux-amd64/data/snapshots/20191118T100200Z-490bd268b68e6a3f 11459543 victoria-metrics-data/snapshots/20191118100200-15D7566ABFAD112D
So VictoriaMetrics is using around 12% less disk space here. The ratio of Prometheus to VictoriaMetrics usage started out higher though, generally has been trending down, and seems to have a bit of a sawtooth pattern:
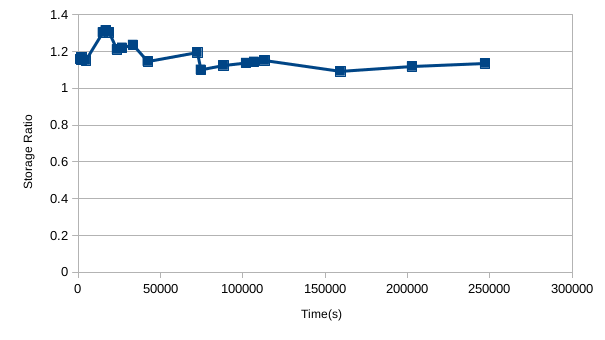
Given the results from my lightning talk, I'd expect this to get to the point where Prometheus had lower usage if I left it running for longer. I don't believe this level of difference is important though, as we're only talking 10% in some direction With a system taking in 1M samples/s and offloading to S3 via something like Thanos that 10% difference only comes to storage costs of a couple hundred of dollars for a full year's data over a year. It's not nothing, but it's only a pretty small factor to be considered along engineer salaries and the other compute costs involved in monitoring.
In summary VictoriaMetrics may use a small bit less disk space than Prometheus depending on usage, however this is at the cost of losing precision, dropping NaNs, and not having the benefits of staleness handling. The indexes are smaller on disk, but lookups are several times less performant compared to a stock Prometheus, before we even get to discuss the much larger amounts of data that are typically involved in distributed systems like Thanos, Cortex, and M3DB. The above also shows the risks of independently implementing a language like PromQL from scratch rather than reusing the Prometheus code like everyone else does, as there's several examples where VictoriaMetrics returns an incorrect result. There's lots of little details you have to get right, and these are only the issues that I came across by chance while playing around. I imagine these issues will gradually be addressed, however I'd advise caution as things stand. Disk is cheap, humans having to deal with subtle and not so subtle semantic issues much less so.
A good next step would be if someone did a full comparison between Thanos, Cortex, and M3DB with larger data volumes, as that's where VictoriaMetrics positions itself.
A response to this post from VictoriaMetrics can be found here.
Need help with Prometheus and clustered storage? Contact us.



No comments.